
Siri from scratch! (Not really.)
Published:
I make fairly heavy use of the voice assistant on my phone for things like setting timers while cooking. As a result, when I spent some time this summer at my in-laws’ place—where there was no cell signal and not-very-good Wi-Fi—I often tried using Siri only to get a sad little “sorry, no Internet :(“ response. (#FirstWorldProblems.)
This reminded me of a tweet I saw a while back:
like 90% of my voice assistant usage is setting timers, math, and unit conversions
— Arkadiy Kukarkin (@parkan) April 19, 2019
can we ship an offline on-device model that does this well and nothing else?
Now, it just so happens that I 1) am a big fan of doing things offline rather than in the cloud, 2) have some experience training speech models, and 3) wanted to procrastinate. (The perfect storm.) So here’s the record of me taking a crack at it.
The goal
The goal is to make a box that can take as input the speech signal and output what the speaker wants. The output takes the form of a dictionary containing the semantics of the utterance1—i.e. the intent, slots, and slot values, and maybe some other fancy things like Named Entities. I shall casually refer to this output simply as the “intent”, a common synecdoche. This is called “spoken language understanding” (SLU).
The “decoupled” approach
The first thing I tried was a straightforward “decoupled” approach: I trained a general-purpose automatic speech recognition (ASR) part and a separate domain-specific natural language understanding (NLU) part.
To train the ASR part, I used LibriSpeech, a big dataset of American English speakers reading audiobooks. (Or rather, my SpeechBrain colleagues did, and I just loaded their best model checkpoint. Thanks, Ju-Chieh + Mirco + Abdel + Peter!)
To train the NLU part, we need text labeled with intents. For this, I wrote a script to generate a bunch of labeled random phrases for the four types of commands I wanted: setting timers, converting units (length, volume, temperature), setting alarms, and simple math. Here’s a few examples:
("how many inches are there in 256 centimeters",
{
'intent': 'UnitConversion',
'slots': {
'unit1': 'centimeter',
'unit2': 'inch',
'amount': 256
}
})
("set my alarm for 8:03AM",
{
'intent': 'SetAlarm',
'slots': {
'am_or_pm': 'AM',
'alarm_hour': 8,
'alarm_minute': 3
}
})
("what's 37.67 minus 75.7",
{
'intent': 'SimpleMath',
'slots': {
'number1': 37.67,
'number2': 75.7,
'op': ' minus '
}
})
I trained an attention model to ingest the transcript and autoregressively predict these dictionaries as strings, one character at a time.
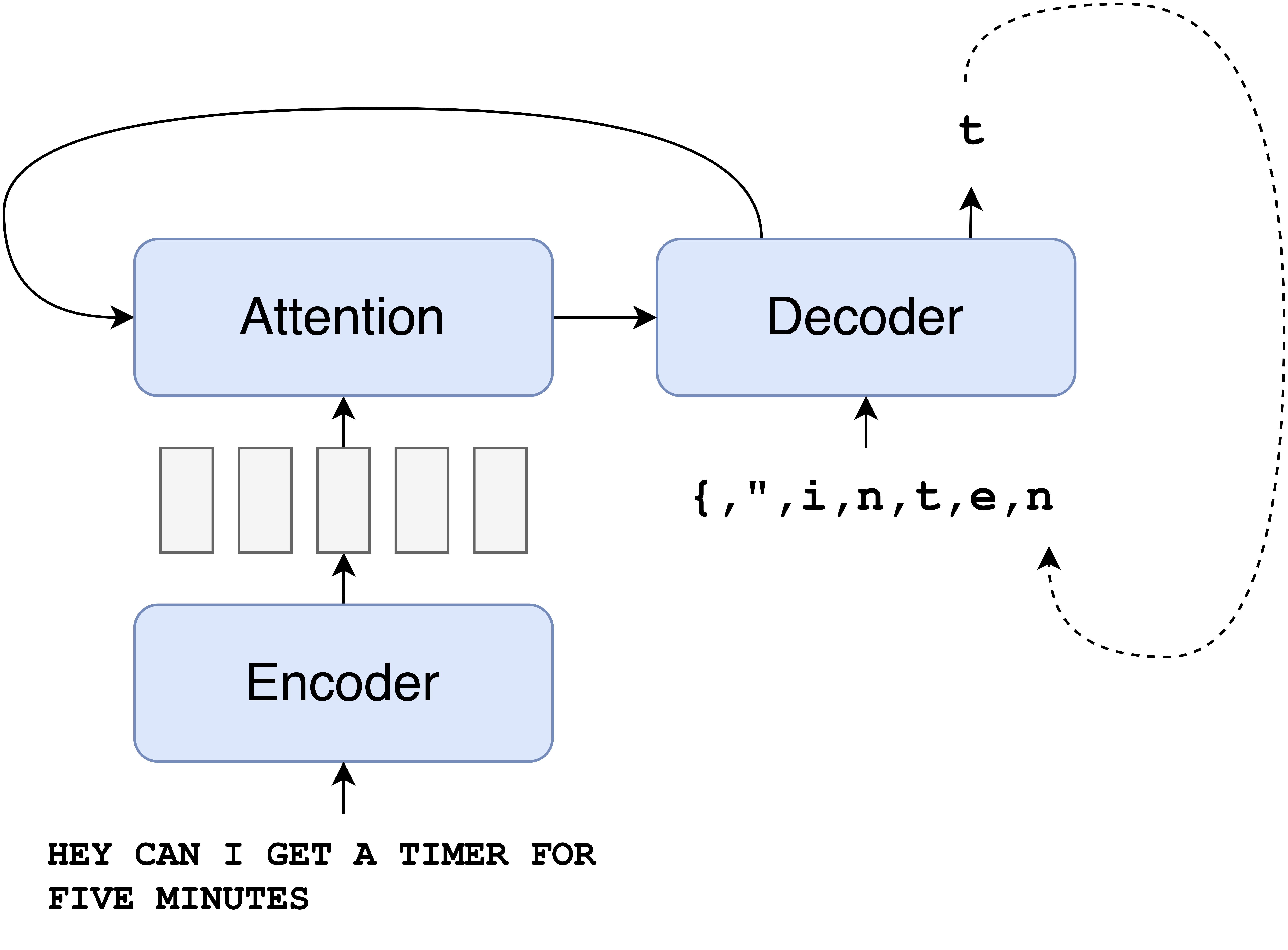
This model gets perfect accuracy on the test transcripts, which makes sense, since this is a pretty simple domain.
Does that mean our system as a whole will get perfect accuracy on test audio? No, because there is the chance that the ASR part will incorrectly transcribe the input and that the NLU part will fail as a result. To measure how well our system works, we need some actual in-domain audio data.
Some end-to-end test (and training) data
So I recorded a few friends and colleagues speaking the generated prompts. My recordees kindly gave me their consent to release their anonymized recordings, which you can find here. I manually segmented and cleaned (= fixed the label, when someone misspoke) their recordings, yielding me a modest 271 audios. (This exercise builds character. I highly recommend it! So does Andrej Karpathy.)
I split the recordings into train/dev/test sets so that each speaker was in only one of the sets, with:
- 144 audios (4 speakers) for the train set (
train-real), - 72 audios (2 speakers) for the dev set (
dev-real), and - 55 audios (5 speakers) for the test set (
test-real).
(For the decoupled approach, we don’t need audio during training, but we will shortly for an alternative approach.)
It’s hard to get meaningful accuracy estimates with only 55 test examples, so I also generated a bunch of synthetic audio (train-synth, dev-synth, test-synth) by synthesizing all my NLU training text data with Facebook’s VoiceLoop text-to-speech model.2 Like I did for the real speakers, I split the 22 synthetic speakers into train/dev/test sets with no speaker overlap.
In total, I generated around 200,000 audios. I couldn’t figure out how to parallelize the generation process—with simple multithreading I ran into some concurrency problems with the vocoder tool called by VoiceLoop—so I just did it sequentially, which took more than a week to finish.
Lucky for you, I’ve uploaded both the real speech and synthesized speech here! I call the complete dataset Timers and Such v0.1. It’s v0.1 because the test set of real speakers is probably too small for it to be used to meaningfully compare results from different approaches. It would be nice to scale this up to more real speakers and make a v1.0 that people can actually use for R&D.
First results
I tested the system out on test-real and test-synth and measured the overall accuracy (= if any slot is wrong, the whole utterance is considered wrong). Here’s the results, averaged over 5 seeds:
| Model | test-real | test-synth |
|---|---|---|
| Decoupled | 23.6% $\pm$ 7.3% | 18.7% $\pm$ 5.1% |
Wow, it’s only getting the answer right a fifth of the time. That sucks! What could the problem be?
Let’s look at some of the ASR outputs for test-real:
True transcript: "SET A TIMER FOR EIGHT MINUTES"
ASR transcript: "SAID A TIMID FOR EIGHT MINUTES"
True transcript: "HOW MANY TEASPOONS ARE THERE IN SIXTY SEVEN TABLESPOONS"
ASR transcript: "AWMAN IN TEASPOILS ADHERED IN SEVEN ESSAYS SEVERN TABLESPOONS"
Now, this ASR model gets a WER of 3% (not SOTA, but good) on the test-clean subset of LibriSpeech. So why do the outputs look so bad here?
One issue is accent mismatch. LibriSpeech has only American English speakers, whereas only 3 of 11 real speakers in Timers and Such have American accents. There’s not much we could do about this, save re-train the ASR model on a more diverse set of accents.
The other issue is language model (LM) mismatch. The ASR model has an LM trained on LibriSpeech’s LM text data. That text data comes from Project Gutenberg books, which is a very different domain: for instance, “SAID” is more likely to appear at the beginning of a transcript from a book than “SET”.
So I trained an LM on the Timers and Such transcripts, and used that as the ASR model’s LM instead of the LibriSpeech LM. This ends up fixing a lot of ASR mistakes, but not all of them.3
| Model | test-real | test-synth |
|---|---|---|
| Decoupled (LibriSpeech LM) | 23.6% $\pm$ 7.3% | 18.7% $\pm$ 5.1% |
| Decoupled (Timers and Such LM) | 44.4% $\pm$ 6.9% | 31.9% $\pm$ 3.9% |
Sort-of end-to-end training: the “multistage” approach
Instead of training on the true transcript, we might want to train the NLU model using the ASR transcript, to make the NLU part more resilient to ASR errors. Google calls this a “multistage” end-to-end SLU model: it still uses distinct ASR and NLU parts, but the complete system is trained on audio data.
Running this experiment, multistage training works a lot better than the decoupled approach, with or without an appropriate LM.
| Model | test-real | test-synth |
|---|---|---|
| Decoupled (LibriSpeech LM) | 23.6% $\pm$ 7.3% | 18.7% $\pm$ 5.1% |
| Decoupled (Timers and Such LM) | 44.4% $\pm$ 6.9% | 31.9% $\pm$ 3.9% |
| Multistage (LibriSpeech LM) | 69.8% $\pm$ 3.5% | 69.9% $\pm$ 2.5% |
| Multistage (Timers and Such LM) | 75.3% $\pm$ 4.2% | 73.1% $\pm$ 8.7% |
For-real end-to-end training: the “direct” approach
Still, there’s a few disadvantages to the multistage ASR-NLU approach.
- We need an intermediate search step to predict a transcript during training. The search is inherently sequential and ends up being the slowest part of training.
- It’s difficult4 to backpropagate through the discrete search into the encoder, so the model can’t learn to give more priority to recognizing words that are more relevant to the SLU task, as opposed to less informative words like “the” and “please”.
- Ultimately, we don’t actually care about the transcript for this application: we just want the intent. By predicting the transcript, we’re wasting FLOPs.5
So: why not train a model to just map directly from speech to intent?6 To quote Vapnik: “When solving a problem of interest, do not solve a more general problem as an intermediate step.”7
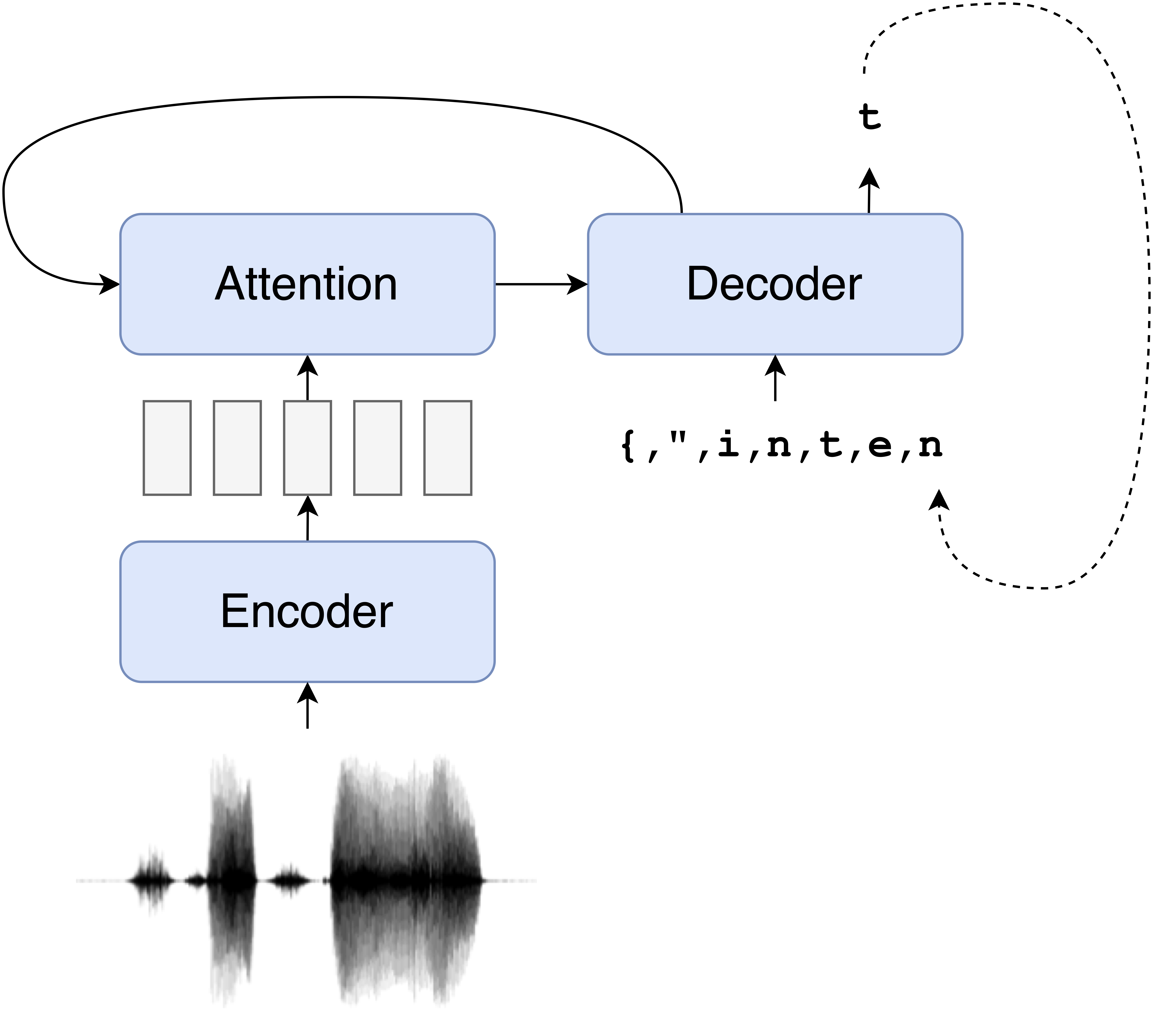
The direct approach faces an additional difficulty: it has to learn what speech sounds like from scratch. To make the comparison with the ASR-based models more fair, we can use transfer learning. This can be done simply by popping the encoder out of the pre-trained LibriSpeech ASR model and using it as a feature extractor in the SLU model.8
We get pretty good results with this approach: around the same performance as the multistage model with an appropriate language model (slightly worse, within a standard deviation). The direct model also trained a lot faster: 1h 42m for one epoch (running on a beastly Quadro RTX 8000), compared with 2h 53m for the multistage model on the same machine.
| Model | test-real | test-synth |
|---|---|---|
| Decoupled (LibriSpeech LM) | 23.6% $\pm$ 7.3% | 18.7% $\pm$ 5.1% |
| Decoupled (Timers and Such LM) | 44.4% $\pm$ 6.9% | 31.9% $\pm$ 3.9% |
| Multistage (LibriSpeech LM) | 69.8% $\pm$ 3.5% | 69.9% $\pm$ 2.5% |
| Multistage (Timers and Such LM) | 75.3% $\pm$ 4.2% | 73.1% $\pm$ 8.7% |
| Direct | 74.5% $\pm$ 6.9% | 96.1% $\pm$ 0.2% |
Notice anything interesting? The direct model performs a lot better on test-synth than the other models. This makes sense: the direct model has access to the raw speech features, so it can learn the idiosyncrasies of the speech synthesizer and recognize the synthetic test speech more easily. (Of course, we don’t care about the performance on synthetic speech; we only care about how well this works for human speakers.)
Are we done?
Did we achieve our goal from the outset of “an offline on-device model that [recognizes numeric commands] well and nothing else”?
As for “on-device”: The model has 170 million parameters, most of which live in the pre-trained ASR part. This requires 680MB of storage using single-precision floats; for reference, right now the maximum app download size for Android is 100MB, so we would probably have a hard time putting this on a phone. We would need to fiddle with the ASR hyperparameters a bit to shrink the encoder, but this is definitely doable. In fact, the direct SLU models I trained in my previous papers had a little over 1 million parameters—this was one of the main selling points for end-to-end SLU models in the original paper.
As for “well”: Does 75% accuracy count as good? Probably not, unless you’re OK with your cooking timer being set for 10 hours instead of 10 minutes now and then. For starters, we saw that the training data—LibriSpeech and the synthetic Timers and Such speech—is almost entirely American English, so we would need to collect some more accents for the training data. But I’m American, so it works well for me! (The linguistic equivalent of “it runs on my machine”.)
Code and data
I wrote the code for all these experiments as a set of recipes to be included in the SpeechBrain toolkit. It’s not available to the public yet, but it will be soon. In the meantime, you can train a model on Timers and Such v0.1 using my older end-to-end SLU code here—though I would recommend waiting until SpeechBrain comes out, since my SpeechBrain SLU recipes are a lot cleaner and easier to use.
The disadvantage of formulating the problem this way is that we need someone to design this output format and write a program to map the intent to a sequence of actions. A better way to formulate the problem might be to use reinforcement learning: let the agent act in response to requests and learn to act to maximize some reward signal (“did the agent do what I want?”), without the need for any hard-coded semantics, as was originally suggested in this paper. The question then becomes: what should our action space look like? High-level actions, like pushing buttons in an app (inflexible, but easier to learn)? Or low-level actions, like reading and writing to locations in memory (flexible, but more difficult to learn)? And can we train the model with some sort of imitation learning or simulation, so that we don’t have to wait forever for it to learn from human feedback? Interesting and challenging questions that I won’t linger on here, but which I’d like to think more about in the future. ↩
I wrote a whole paper about this idea! ↩
We could probably do better using an FST-based speech recognizer, which would allow us to perfectly constrain the model to only outputting sentences that fit a certain grammar (that is, the “G” part of “HCLG”). ↩
Though not impossible, using tricks like Gumbel-Softmax and the straight-through estimator. ↩
A fourth (more subtle) disadvantage of ASR-based SLU models is that the speech signal may contain information that is not present in the transcript. For example, sarcasm is not always apparent from just looking at a transcript. This is not really relevant for the simple numeric commands we’re dealing with here, but for more general-purpose robust language understanding in robots of the future, non-transcript information might be crucial, in addition to other multimodal information like visual cues. ↩
This was proposed by my friend Dima Serdyuk in his 2018 ICASSP paper. A few other groups—including Fluent.ai, where I worked before my PhD—had had similar ideas earlier, but as far as I’m aware, Dima was the first to get a truly end-to-end SLU model to work, without any sort of ASR-based inductive bias or transfer learning. ↩
Actually, there are tons of examples of solving a more general problem yielding better results for the problem of interest, like language model pre-training for text classification. But as the amount of data we have for the problem of interest goes to infinity, Vapnik is right. ↩
In this paper, I proposed a somewhat more complicated way of pre-training the encoder using phoneme and word targets from a forced aligner. The idea was that using word targets would be ideal (and more amenable to an idea I had for using pre-trained word embeddings to help the model understand the meaning of synonyms not present in the SLU training set), but using too many word targets would be expensive, which is why we used phoneme targets as well. Using the pre-trained ASR model’s encoder was a lot simpler to implement, though I haven’t done a fair comparison with the forced alignment approach yet. ↩