
End-to-end models falling short on SLURP
Published:
There’s a hot new dataset for spoken language understanding: SLURP. I’m excited about SLURP for a couple reasons:
- It’s way bigger and more challenging than existing open-source SLU datasets:
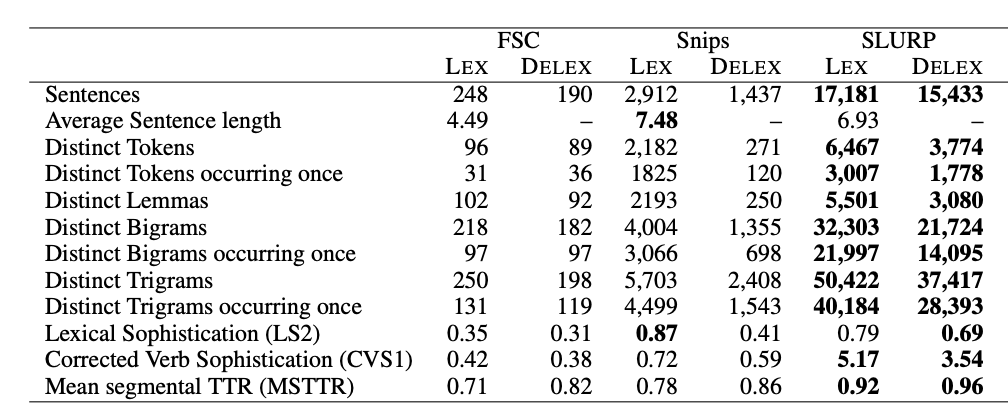
- The authors found that an end-to-end model did not work:
We have tested several SOTA E2E-SLU systems on SLURP, including (Lugosch et al., 2019b) which produces SOTA results on the FSC corpus. However, re-training these models on this more complex domain did not converge or result in meaningful outputs. Note that these models were developed to solve much easier tasks (e.g. a single domain).
Having just written a SpeechBrain recipe for end-to-end SLU with my much simpler Timers and Such dataset, I thought I’d give that recipe a whirl on SLURP. The model used in the recipe looks like this:
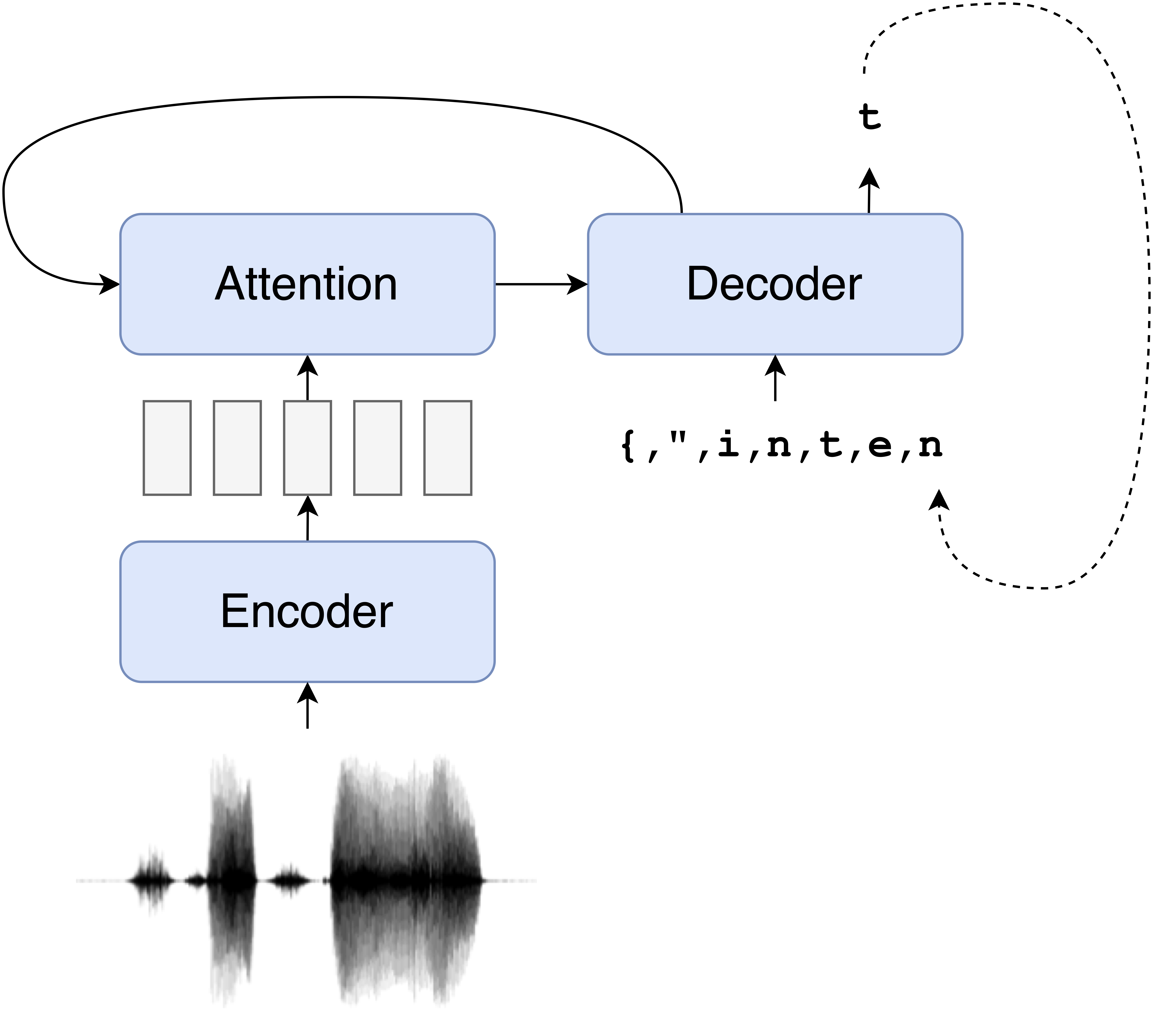
The output dictionaries for SLURP look a bit different from the ones in Timers and Such or Fluent Speech Commands:
{
"scenario": "alarm",
"action": "query",
"entities": [
{"type": "event_name", "filler": "dance class"}
]
}
But—much like a honey badger—our autoregressive sequence-to-sequence model doesn’t care. It just generates the dictionary character-by-character, no matter what the format looks like.
The authors of the SLURP paper provide baseline results with a more task-specific model, HerMiT, which uses an ASR model to predict a transcript and a conditional random field for each of (scenario, action, entities). The outputs are generated using the Viterbi algorithm.
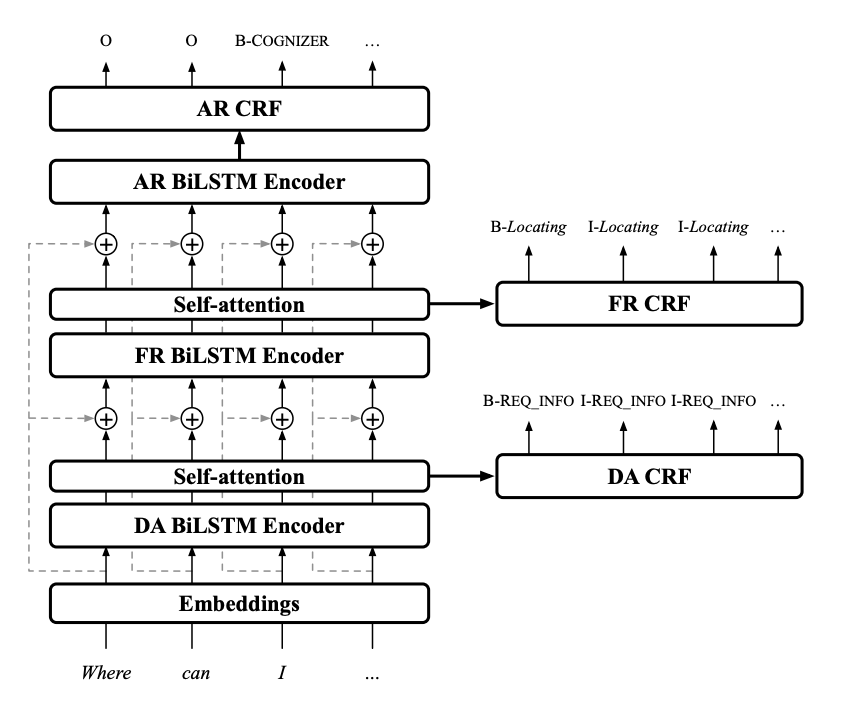
The authors kindly released their tool for computing performance metrics, including a new “SLU-F1” metric they propose. I used this tool and got the following results (EDIT: I left the model training a little longer and updated the numbers EDIT EDIT: I got rid of a coverage penalty term in the beam search and updated the numbers again):
| Model | scenario (accuracy) | action (accuracy) | intent (accuracy) | Word-F1 | Char-F1 | SLU-F1 |
|---|---|---|---|---|---|---|
| End-to-end | 81.73 | 77.11 | 75.05 | 61.24 | 65.42 | 63.26 |
| HerMiT | 85.69 | 81.42 | 78.33 | 69.34 | 72.39 | 70.83 |
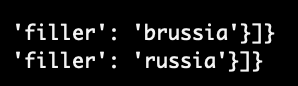
Turns out HerMiT does way better than our end-to-end model. This isn’t totally surprising because HerMiT has a lot of structure built in that our autoregressive model has to learn from scratch. For instance, I don’t think it’s possible for their model to output "brussia" (one of the more charming output mistakes I noticed early in training).
Another difference is that their ASR model is trained on Multi-ASR, a massive 24,000 hour dataset formed by Captain-Planeting the LibriSpeech, Switchboard, Fisher, CommonVoice, AMI, and ICSI datasets—whereas my encoder is only pre-trained using the 1,000 hours of LibriSpeech.
So: how much of the gap is due to more/better audio? The authors also report some results when applying HerMiT to the gold transcripts instead of the ASR output; similarly, we can feed the gold transcripts into our sequence-to-sequence model instead of audio and compare the results (EDIT again, I let the model train a bit longer/got rid of the pesky coverage penalty and updated the numbers):
| Model | scenario (accuracy) | action (accuracy) | intent (accuracy) |
|---|---|---|---|
| End-to-end (text input, gold transcripts) | 90.81 | 88.29 | 87.28 |
| HerMiT (gold transcripts) | 90.15 | 86.99 | 84.84 |
Here the simple sequence-to-sequence model actually does about as well as HerMiT (EDIT actually a bit better!). This suggests that the audio side of things is more where our problems lie.
In summary, I have attempted to defend the honor of end-to-end models: we can indeed train one on SLURP and get semi-reasonable outputs. Note, though, that I’ve done no hyperparameter tuning on the model (except to increase the number of training epochs and getting rid of the coverage penalty term), so it’s possible we could do better with a little elbow grease—maybe starting by swapping out the now-unfashionable RNNs I used in the encoder and decoder with ✨Transformers✨.